
Um servidor lento é um dos problemas mais críticos e estressantes em qualquer infraestrutura moderna. Seja hospedando um blog WordPress de alto tráfego, um e-commerce, um SaaS ou uma aplicação corporativa, a lentidão impacta diretamente suas métricas de SEO, reduz a taxa de conversão e destrói a experiência do usuário.
O erro mais comum cometido por administradores ao enfrentar uma queda de performance é assumir automaticamente que o problema está na falta de processador (CPU). Na prática, o gargalo pode estar escondido no disco, na memória, na rede, na camada de virtualização ou até mesmo em uma arquitetura mal dimensionada.
Neste guia técnico completo, você aprenderá a diagnosticar corretamente a raiz da lentidão em ambientes VPS, Servidor Dedicado ou instâncias Cloud, utilizando a metodologia profissional de troubleshooting (como o método USE – Utilization, Saturation, Errors).
O load average é apenas um dos indicadores utilizados para medir a saúde de um sistema Linux. Para entender todos os fatores que impactam o desempenho de um servidor, veja também nosso guia completo sobre diagnóstico de performance em servidores Linux
Um dos gargalos mais comuns em servidores Linux está relacionado ao subsistema de armazenamento. Mesmo quando CPU e memória parecem normais, latências de disco podem causar lentidão significativa em aplicações. Para entender melhor como diagnosticar esse tipo de problema, veja também o guia sobre gargalos de I/O de disco em servidores Linux.
1. O Que Realmente Significa um “Servidor Lento”?
Tecnicamente falando, lentidão não é sinônimo de “CPU em 100%”. Significa, na verdade, que existe um (ou mais) recurso saturado causando aumento na fila de espera e, consequentemente, latência nas respostas.
Uma máquina pode apresentar respostas demoradas devido a:
- Processador sobrecarregado (fila de execução cheia).
- Memória insuficiente (causando paginação excessiva).
- I/O de disco saturado (o hardware de armazenamento não acompanha os pedidos).
- Problemas de conectividade e gargalos no link de rede.
- Overselling e limitações impostas pela virtualização (hypervisor).
Diagnosticar a lentidão exige a análise de métricas reais, e não tentativas cegas de otimização.
2. Metodologia Profissional de Diagnóstico
Nunca comece alterando configurações do my.cnf ou do nginx.conf sem antes ter certeza de onde está o problema. Siga esta ordem cronológica de investigação:
- Verificar a média de processos (Load Average).
- Analisar a saturação de CPU.
- Avaliar a disponibilidade de Memória RAM e Swap.
- Checar a latência e o uso de Disco (I/O).
- Validar gargalos na Rede.
3. CPU: O Primeiro Suspeito (Mas Nem Sempre o Culpado)
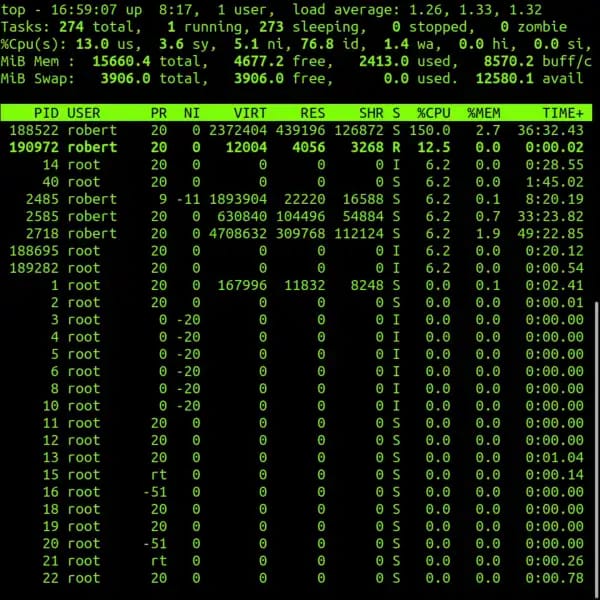
O processador costuma ser o primeiro recurso verificado. Para isso, utilize os comandos clássicos:
uptime top htop
O que você deve observar:
- O Load Average é consistentemente maior que o número de núcleos físicos/virtuais.
- O uso de CPU permanece acima de 80% de forma sustentada.
- A coluna
%st(Steal Time) notop.
Atenção especial para ambientes VPS: Se você notar um steal time alto (geralmente acima de 5%), isso significa que o hypervisor da empresa de hospedagem está “roubando” ciclos de processamento da sua máquina para atender outros clientes no mesmo nó (overselling). Isso deixa qualquer servidor lento, mesmo que os seus serviços internos estejam consumindo quase nada.
4. Memória: O Gargalo Silencioso

A falta de memória geralmente mascarada faz com que o sistema operacional recorra ao disco para compensar a RAM faltante. Utilize as ferramentas de leitura:
free -h vmstat 1 dmesg | grep -i oom
Sinais claros de saturação:
- Uso constante e crescente da partição de Swap.
- Valores altos nas colunas
si(Swap In) eso(Swap Out) novmstat. - Registros do OOM Killer (Out of Memory) matando processos (frequentemente o MariaDB/MySQL) nos logs do kernel.
Em pilhas web (Nginx, PHP-FPM, MariaDB), a memória costuma se esgotar rapidamente quando parâmetros como o innodb_buffer_pool_size estão mal dimensionados ou quando o pm.max_children do PHP permite mais instâncias simultâneas do que a RAM suporta.
Para identificar corretamente o problema, é essencial analisar diferentes métricas do sistema. Veja também:
5. Disco (I/O): O Verdadeiro Vilão

Se existe um campeão de reclamações quando se trata de um servidor lento, é a lentidão nas operações de leitura e gravação no armazenamento. Para diagnosticar problemas na camada de bloco:
iostat -x 1 iotop
Indicadores críticos:
- A métrica
%utilpróxima de 100%. - O tempo de espera (
await) excessivamente alto (acima de 20ms para SSDs indica problema). - Alto valor de
wa(I/O wait) no comandotop.
O disco fica saturado por rotinas de backup rodando em horário comercial, storage compartilhado de baixa qualidade na nuvem ou simplesmente pela ausência de discos NVMe lidando com bancos de dados muito transacionais.
Problemas de I/O de disco em servidores Linux podem causar filas de processos e aumento no tempo de resposta das aplicações. Entenda como investigar esse cenário em I/O de disco servidor Linux: como resolver gargalos.
Identificar corretamente o gargalo exige analisar múltiplos indicadores do sistema, incluindo load average, uso de CPU, latência de disco e consumo de memória. Esse processo faz parte de uma análise mais ampla de diagnóstico de performance em servidores Linux em produção.
6. Rede: A Latência Invisível
Às vezes, os recursos internos da máquina estão ociosos, mas a aplicação demora a carregar. Isso pode ser um gargalo de conectividade.
iftop ss -s ping -c 10 destino
Verifique se a largura de banda não atingiu o limite do link (ex: gargalo em links de 1Gbps) ou se o servidor está recebendo uma enxurrada de conexões SYN_RECV, o que pode indicar um ataque DDoS de camada de rede exaurindo os sockets.
7. Diferenças no Diagnóstico por Ambiente
A origem de um servidor lento muda dependendo de onde ele está hospedado:
Em VPS (Virtual Private Server)
O calcanhar de aquiles costuma ser o compartilhamento de recursos. Monitore de perto o CPU Steal (%st) e o I/O de disco, pois você divide esses barramentos com dezenas de outros usuários.
Em Servidores Dedicados (Bare Metal)
Como você tem controle total do hardware, se o ambiente apresentar sobrecarga, as causas típicas são discos mecânicos falhando, RAID mal configurado ou hardware subdimensionado para o tráfego que o seu projeto atingiu.
Na Cloud (AWS, Azure, GCP, DigitalOcean)
Na nuvem pública, o problema frequentemente é financeiro e arquitetural:
- Instâncias da família “Burstable” (como as T3 da AWS) que esgotaram seus créditos de CPU.
- Discos de rede (Block Storage / EBS) que atingiram o limite de IOPS provisionados.
8. Checklist de Solução para Aplicações Web (WordPress)
Como muitos SysAdmins gerenciam pilhas LAMP/LEMP, foque nestas áreas de otimização se o hardware não for o culpado:
- Cache em Memória: O Redis ou Memcached está rodando e integrado para evitar consultas repetitivas no MariaDB?
- FastCGI Cache: O cache a nível de servidor web (Nginx/LiteSpeed) está ativo para páginas não logadas?
- Slow Queries: Ative o
slow_query_logdo banco de dados para encontrar plugins ou queries não indexadas que estão derrubando o disco.
Conclusão
Resolver o problema de um servidor lento nunca deve ser tratado com achismo ou scripts copiados cegamente da internet. O processo exige investigação baseada em fatos: identifique qual barramento (CPU, Memória, Disco ou Rede) é o verdadeiro gargalo antes de agir.
Bons administradores de sistemas medem, isolam o problema e só então aplicam a otimização. Com a metodologia certa e o uso prático de ferramentas nativas do Linux, você garante ambientes de alta disponibilidade, escaláveis e prontos para qualquer pico de acesso.
Resolver um problema de servidor lento não depende apenas de aumentar recursos ou migrar infraestrutura. É fundamental compreender como CPU, memória, disco e rede trabalham juntos. Por isso, recomendamos também o guia completo sobre como analisar performance de servidores Linux de forma integrada.
Veja Mais:
I/O de disco servidor Linux: Como Resolver Gargalos
Load Average no Linux: Como Interpretar Corretamente
Performance de Servidores Linux: Guia Completo 2026
CPU 100% no Linux: O Que Verificar Primeiro no Servidor
Como Usar vmstat para Achar Gargalo no Linux em Minutos
Como Achar Gargalo com Iostat: Guia Definitivo e Prático
Iowait Alto: Causas Reais e Soluções
Swap Alto com RAM Livre: Por Que Isso Acontece e como Resolver
Guia Completo de Monitoramento Linux com vmstat, iostat e sar
Tuning de sysctl para Produção: Guia Definitivo de Performance Linux
Como Ajustar limits.conf no Linux: Guia para Alta Performance
OOM Killer e MySQL: Como Evitar que o Linux Mate seu Banco de Dados
Memory Leak Linux: Como Detectar e Corrigir
Saiba Mais:
No space left on device com espaço livre? Como resolver (Guia Completo)
Como identificar processo que consome CPU no Linux (Guia Completo)
Como Limitar CPU por Processo no Linux com cgroups (Guia Completo)
Upgrade de CPU ou Otimizar? Guia Completo
RAM Cheia no Linux: O Guia Definitivo para Resolver Travamentos em 2026
Buffers e Cache: Quando Deixam de Ajudar e Viram um Problema?
Out of Memory (OOM): Causas Reais, Diagnóstico e Como Resolver
Saiba Mais:
Como evitar OOM Killer Linux em Produção: Guia Definitivo 2026
Gargalo no Linux: Como Identificar se o Problema é CPU ou RAM?
Disco Lento no Linux: Guia Completo para Identificar e Resolver
Latência de Disco no Linux Alta: Causas, Diagnóstico e Soluções
Como Limpar Cache de Memória no Linux: O Guia Definitivo
Como Testar Velocidade de Disco no Linux (Guia Completo)
Performance de Armazenamento NVMe vs RAID: O Guia Definitivo 2026
Throughput vs IOPS no Linux: Guia Definitivo de Performance [2026]
Reduzir Escrita em Disco Linux: Guia Completo para Melhorar Performance
Logs Consumindo Disco? Como Controlar e Limpar o Linux (Guia 2026)