
cache de memória. Vou detalhar com cuidado, porque é um tema sutil, especialmente em CPUs modernas.
1️⃣ Tipos de cache de memória
Em processadores modernos, a hierarquia de memória é assim:
| Nível | Localização | Latência típica | Tamanho típico |
|---|---|---|---|
| L1 | Dentro do núcleo da CPU | 1–5 ciclos | 32–128 KB |
| L2 | Dentro do núcleo, mas maior e mais lenta | 10–20 ciclos | 256 KB – 1 MB |
| L3 | Compartilhada entre núcleos | 30–50 ciclos | 4–64 MB |
| RAM | Fora do CPU | 50–200 ns | GBs |
| Disco/SSD | Armazenamento secundário | μs a ms | TBs |
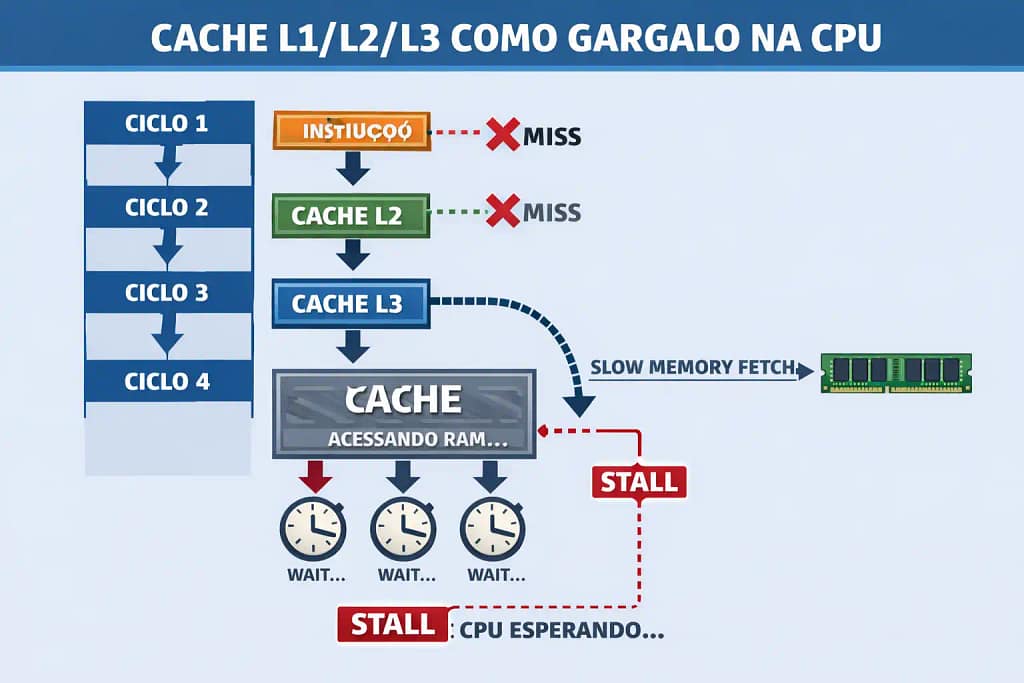
O objetivo do cache é reduzir o acesso à RAM lenta. Mas, ironicamente, ele pode virar gargalo.
2️⃣ Como o cache vira gargalo
- Cache miss frequente
- Quando o dado que a CPU precisa não está no cache (miss), ela precisa buscar na RAM, causando stall.
- Ex.: Processos que acessam grandes matrizes de forma não sequencial ou algoritmos com padrões de acesso aleatório.
- Tamanho insuficiente
- Se os dados ativos não cabem no L1/L2/L3, a CPU fica constantemente esperando pela RAM.
- Aplicações científicas ou bancos de dados grandes podem gerar isso.
- Contention em cache compartilhado
- L3 é compartilhado entre núcleos. Muitos núcleos lendo/escrevendo podem causar throttling, porque alguns dados são constantemente invalidados ou substituídos.
- False sharing
- Dois threads acessam variáveis diferentes, mas na mesma linha de cache. Isso força sincronização desnecessária e invalida linhas de cache, degradando performance.
- Prefetching ineficiente
- CPUs tentam “adivinhar” os dados que serão usados. Se o padrão de acesso for imprevisível, o prefetch traz dados errados, desperdiçando banda de cache.
3️⃣ Sintomas de gargalo de cache
- Alta latência de memória medida via ferramentas como
perfoulikwid. - CPU com baixo IPC (Instructions per Cycle) mesmo com alto uso.
- Aumento de stall cycles em perf counters (
CACHE_MISSES,MEM_LOAD_RETIRED). - Slowdowns em loops de dados grandes ou aplicações multithreaded.
4️⃣ Como mitigar
- Otimização de código: acessar arrays/matrizes de forma sequencial (localidade espacial).
- Reduzir false sharing: alinhar variáveis e separar dados por núcleo.
- Ajuste de threads: evitar sobrecarregar núcleos que compartilham cache L3.
- Algoritmos cache-friendly: bloquear (tiling) matrizes em blocos que cabem no L1/L2.
- Hardware: CPUs com caches maiores ou com melhores políticas de prefetch.
FAQ
É quando o dado que a CPU precisa não está no cache e precisa ser buscado na RAM, aumentando a latência.
L1 é o mais rápido e menor, L2 é intermediário, e L3 é maior, mais lento e compartilhado entre núcleos.
Ferramentas como perf, likwid ou monitoramento de IPC podem indicar stalls e cache misses elevados.
Sim, pois threads diferentes invalidam linhas de cache desnecessariamente, reduzindo performance.
Reorganizando dados, ajustando threads, usando algoritmos cache-friendly e, se possível, hardware com maior cache